
Amazon AthenaのIcebergのVACUUM・OPTIMIZE実行時のS3上のデータファイルについて確認してみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
データ事業本部 インテグレーション部 機械学習チームの鈴木です。
Amazon Athenaでは、Icebergテーブル向けにVACUUMとOPTIMIZEのメンテナンスコマンドが提供されていますが、これらを実行すると実際のところS3上のデータファイルがどのように変わるのか確認してみました。
Icebergテーブルをメンテナンスコマンドなしで運用していると、S3上でファイルがたくさんできることで性能低下やコスト増につながります。意図せぬパフォーマンス低下や課金が起こった際に、適切に対応ができるよう、簡単な例でメンテナンスコマンド実行時にどのようなことが起こるのか把握していると便利です。
メンテナンスコマンドについて
Amazon Athenaでは、Icebergテーブル向けにVACUUMとOPTIMIZEのメンテナンスコマンドが提供されています
VACUUMはスナップショットの期限切れと孤立ファイルの削除を実行します。
スナップショットの期限は、テーブルプロパティのvacuum_max_snapshot_age_secondsで指定され、デフォルトの値は432000秒(5日)です。VACUUMを実行すると、この値を過ぎたスナップショットが期限切れとなり、削除されます。
孤立ファイルは、以下で紹介するOPTIMIZEコマンドなどを実行した際に、テーブルから参照されなくなったデータファイルを指します。これもVACUUMを実行すると削除されます。
OPTIMIZEはテーブルに対する操作を繰り返すうちにできるデータファイルをまとめるためのコマンドになります。
まとめたデータファイルは新しいものを作成します。
メンテナンスコマンド実行時のデータファイルの変化を確認する
上記2つのメンテナンスコマンドを実行した際に、Icebergテーブルのデータの実体であるS3バケット上のデータファイルがどのように作成・削除されるか、簡単な例で確認しました。
1. 準備
Icebergテーブルを作成するため、まずはS3バケットに配置したUCI Machine Learning RepositoryのIris Data Setを検索できるHive形式のirisテーブルを作成しておきました。
このデータセットは、下記リンクにて公開されています。
2. Icebergテーブルの作成
以下のように、CTASでiris_iceberg_parquetテーブルを作成しました。このテーブルはIcebergテーブルとなっています。S3バケット名は自身のものに読み替えてください。
CREATE TABLE iris_iceberg_parquet
WITH (table_type = 'ICEBERG',
format = 'PARQUET',
location = 's3://S3バケット名/iris_iceberg_parquet/',
is_external = false,
partitioning = ARRAY['species']
)
AS SELECT * FROM iris;
この時点でデータファイルを確認すると、以下のように3つのパーティションに分割されています。これはpartitioningでspeciesを指定しているためです。(3品種分のデータが入っているため)
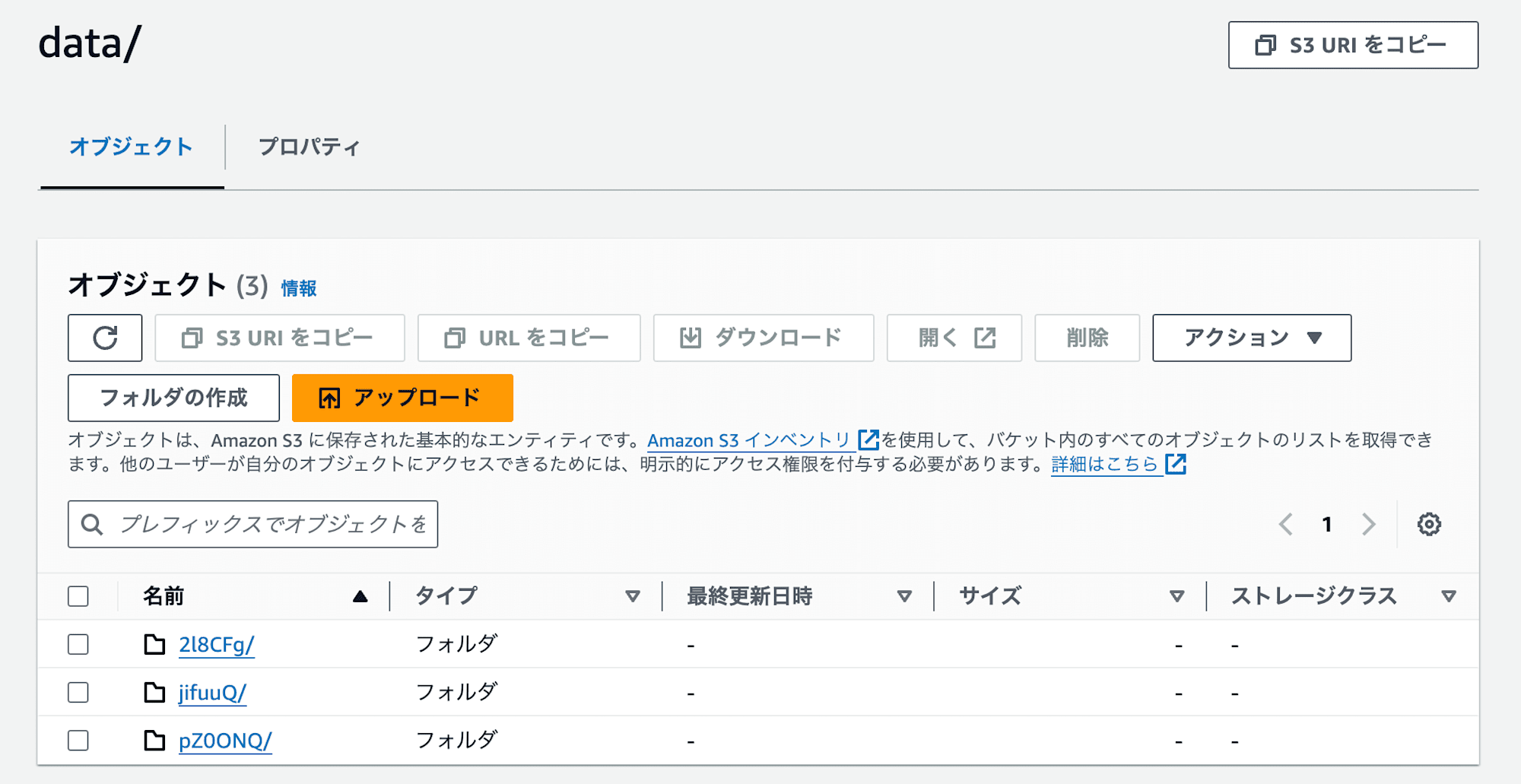
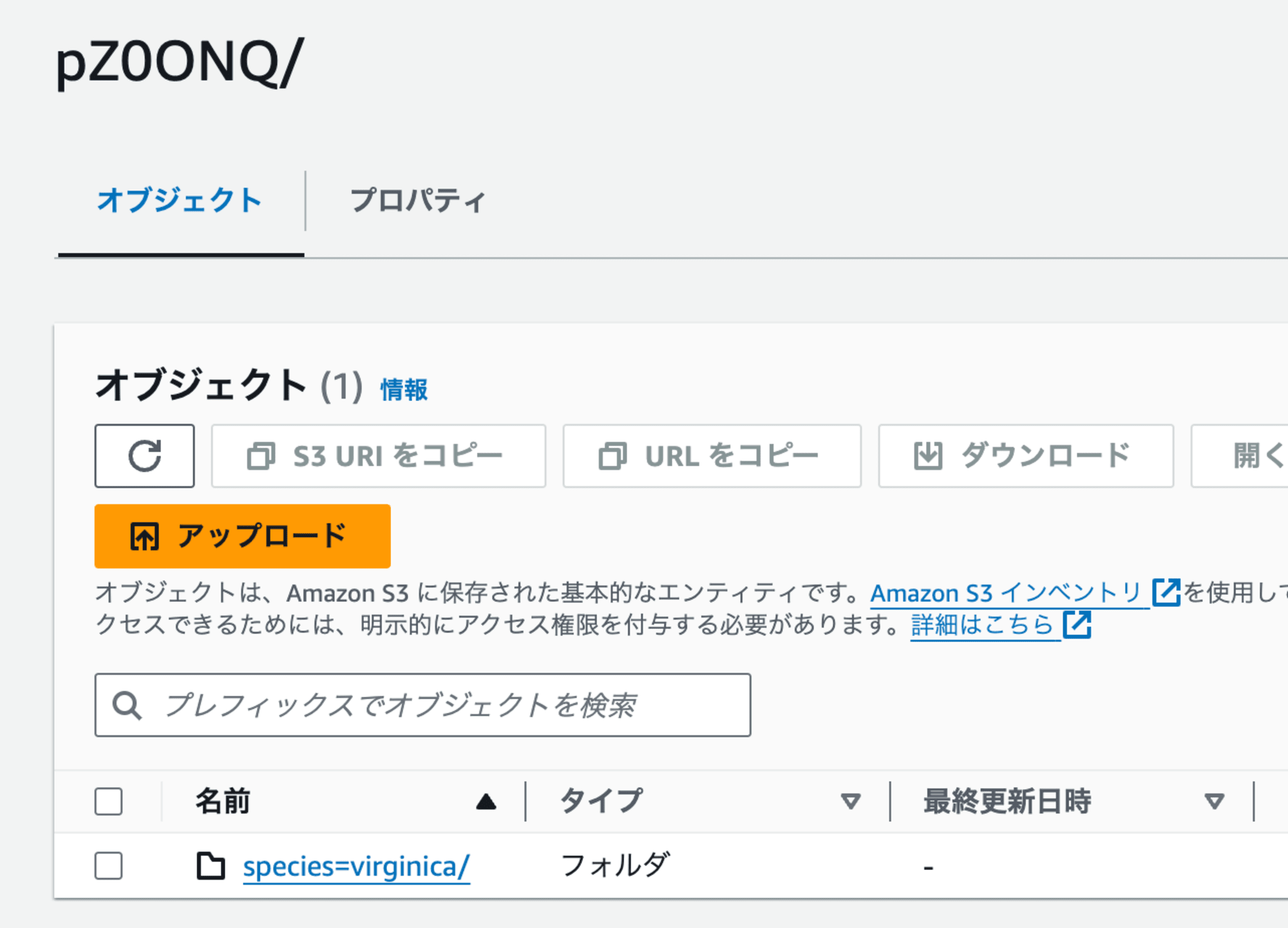
試しに1つ見てみると、以下のように特定の品種のレコードが入っていることが分かります。
3. データのUPDATE
今回はデータをUPDATEして、削除ファイルを作成します。AthenaのIcebergテーブルのUPDATEは、INSERT INTOとDELETEを組み合わせた動きをします。(参考:UPDATE - Amazon Athena)
UPDATE iris_iceberg_parquet SET sepal_length=10 WHERE species='setosa';
このSQLを実行すると、ファイルが5つになりました。
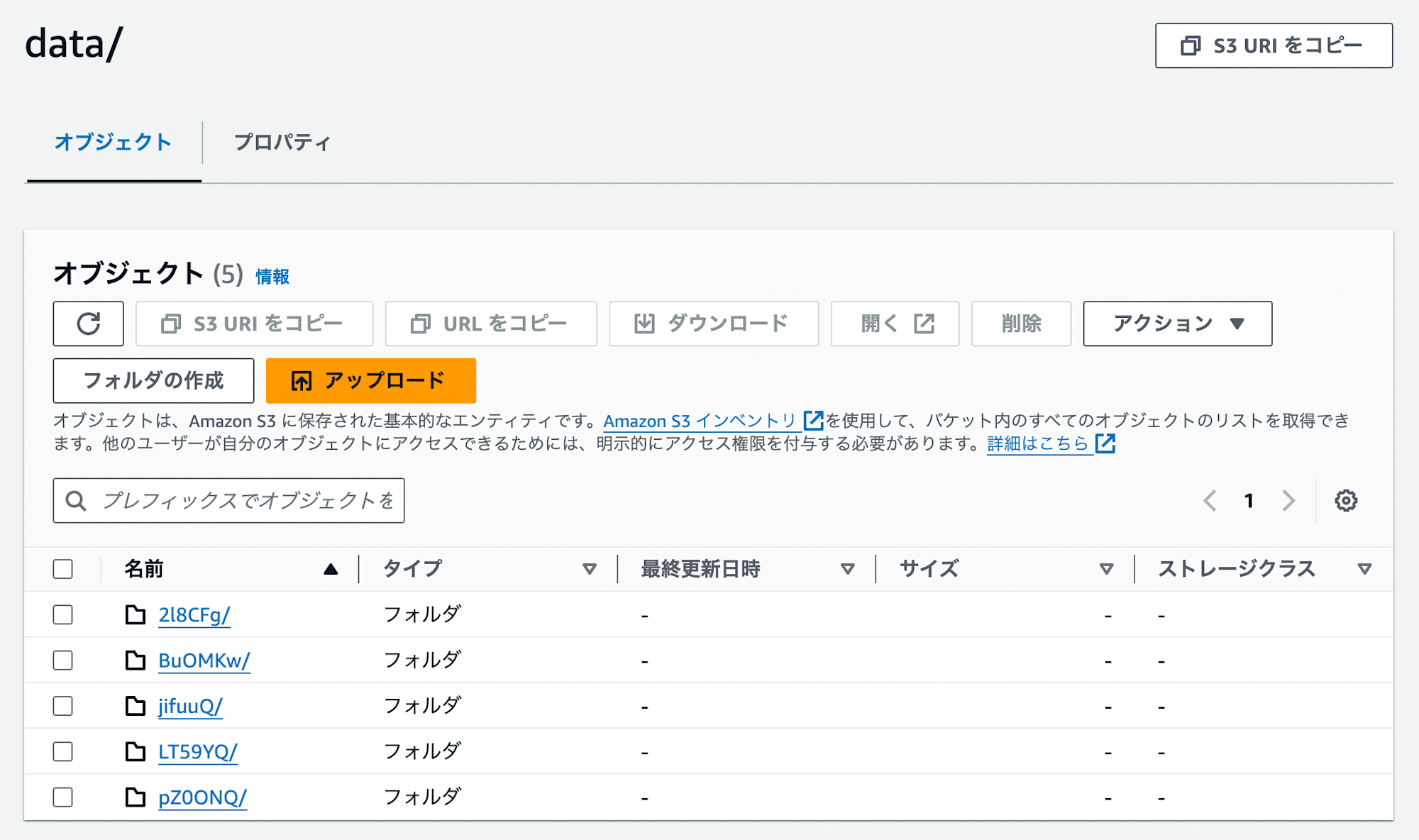
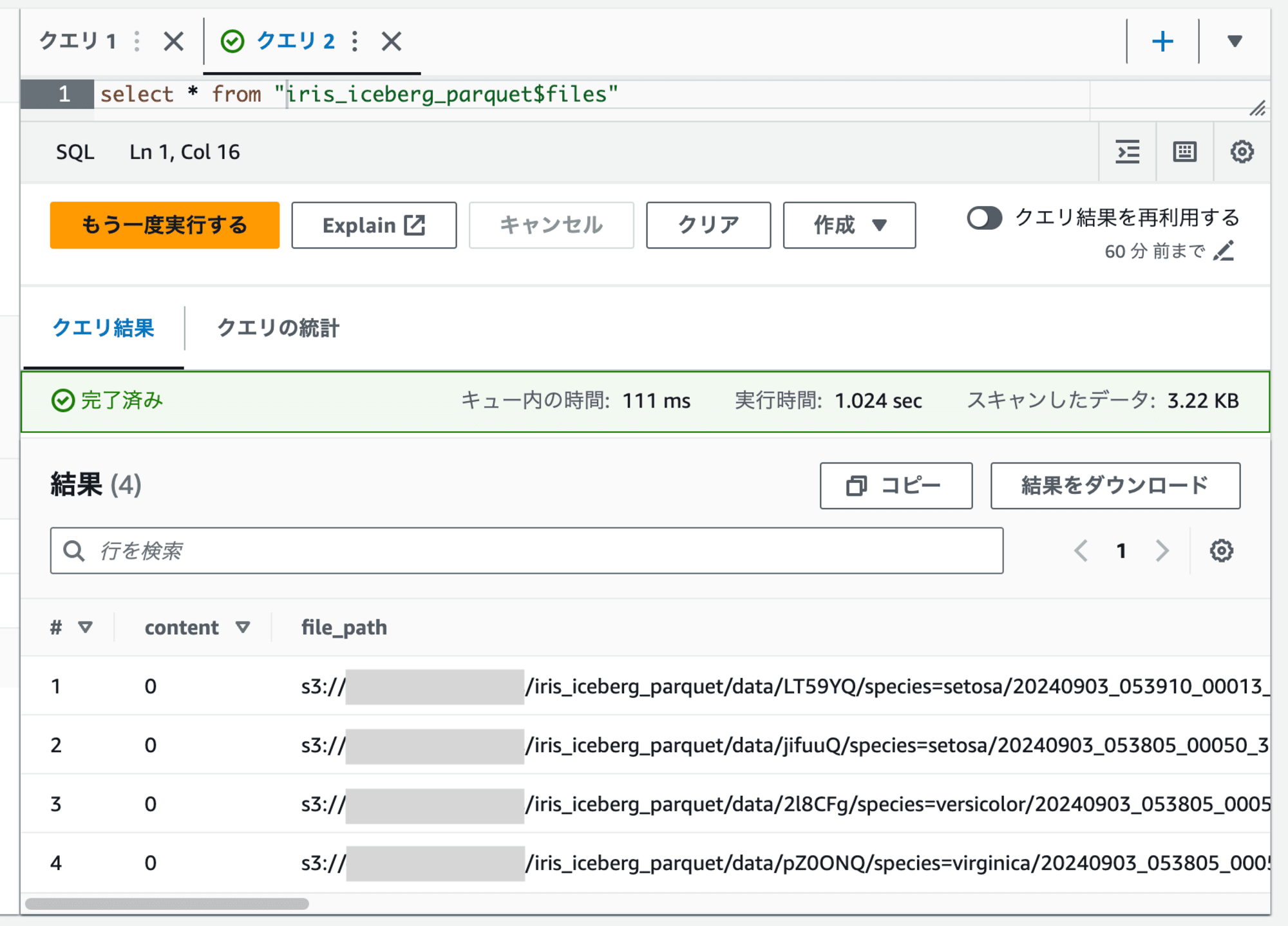
テーブルが参照しているデータファイルを確認すると4つあり、UPDATE後のデータができていました。(5つ目のファイルは削除ファイルでした。)
4. OPTIMIZEの実行
OPTIMIZEを実行し、データファイルをより最適化されたレイアウトに書き換えました。
OPTIMIZE iris_iceberg_parquet REWRITE DATA USING BIN_PACK;
テーブルから参照されるデータファイルは3つになりました。
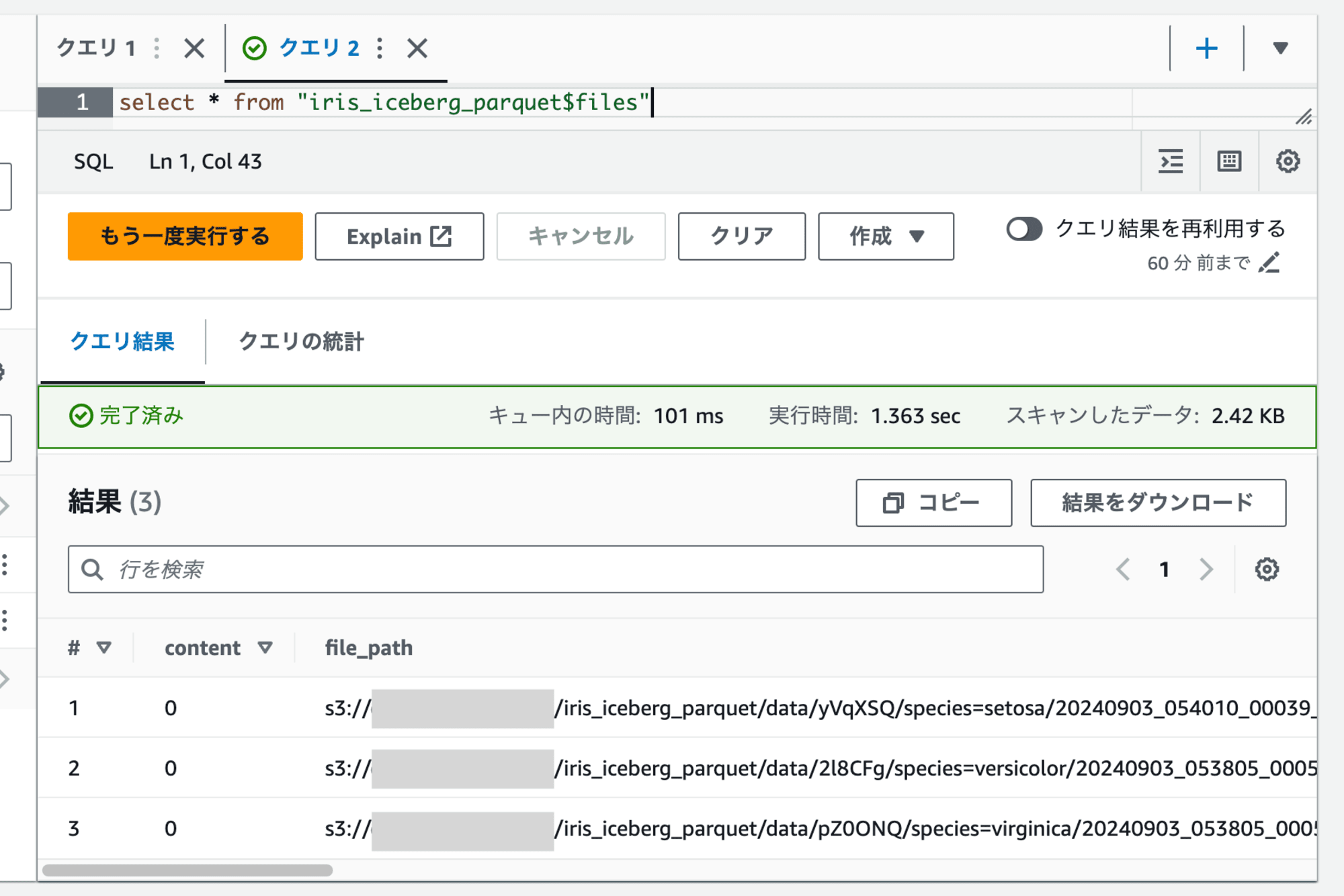
setosaのパーティションのパスが、OPTIMIZE実行前のものと異なっていることが分かります。
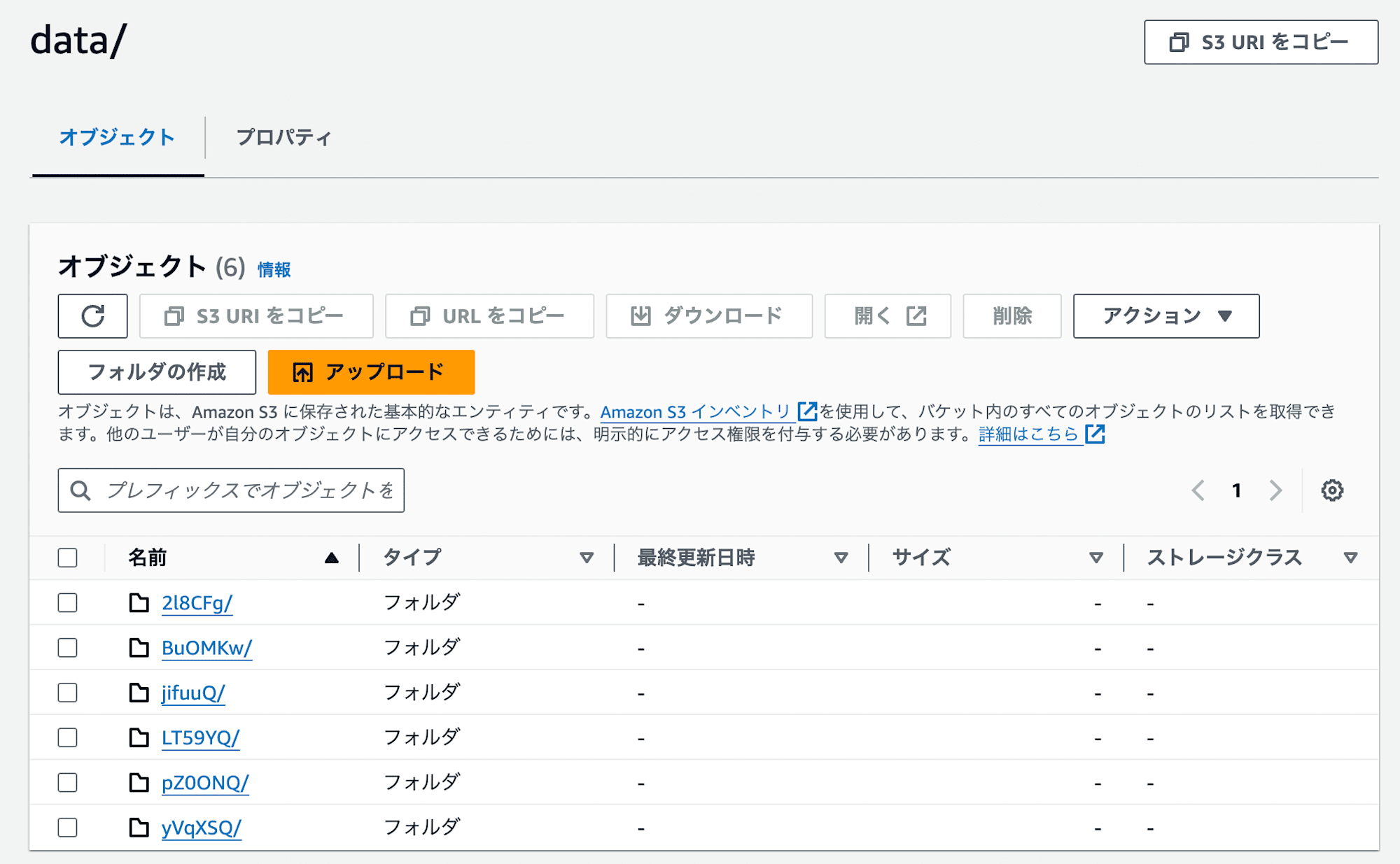
一方、S3上は新しいファイルが追加され、6つになっていました。OPTIMIZEで行われるのはより最適化されたレイアウトのデータファイルを新しく追加することであることが分かります。
5. VACUUMの実行
最後に、VACUUMを実行して不要なファイルを削除しました。
まず、以下のコマンドを実行しました。
VACUUM iris_iceberg_parquet;
このとき、データファイルは削除されませんでした。理由としては、VACUUMは期限が切れたスナップショットを削除しますが、期限はテーブルプロパティのvacuum_max_snapshot_age_secondsで決められており、432000秒(5日間)となっているためです。
今回は検証のため、この期限を以下のコマンドで意図的に短く変更しました。
ALTER TABLE iris_iceberg_parquet SET TBLPROPERTIES ('vacuum_max_snapshot_age_seconds' = '60')
60秒待って再度VACUUMを実行すると、データファイルが3つになりました。
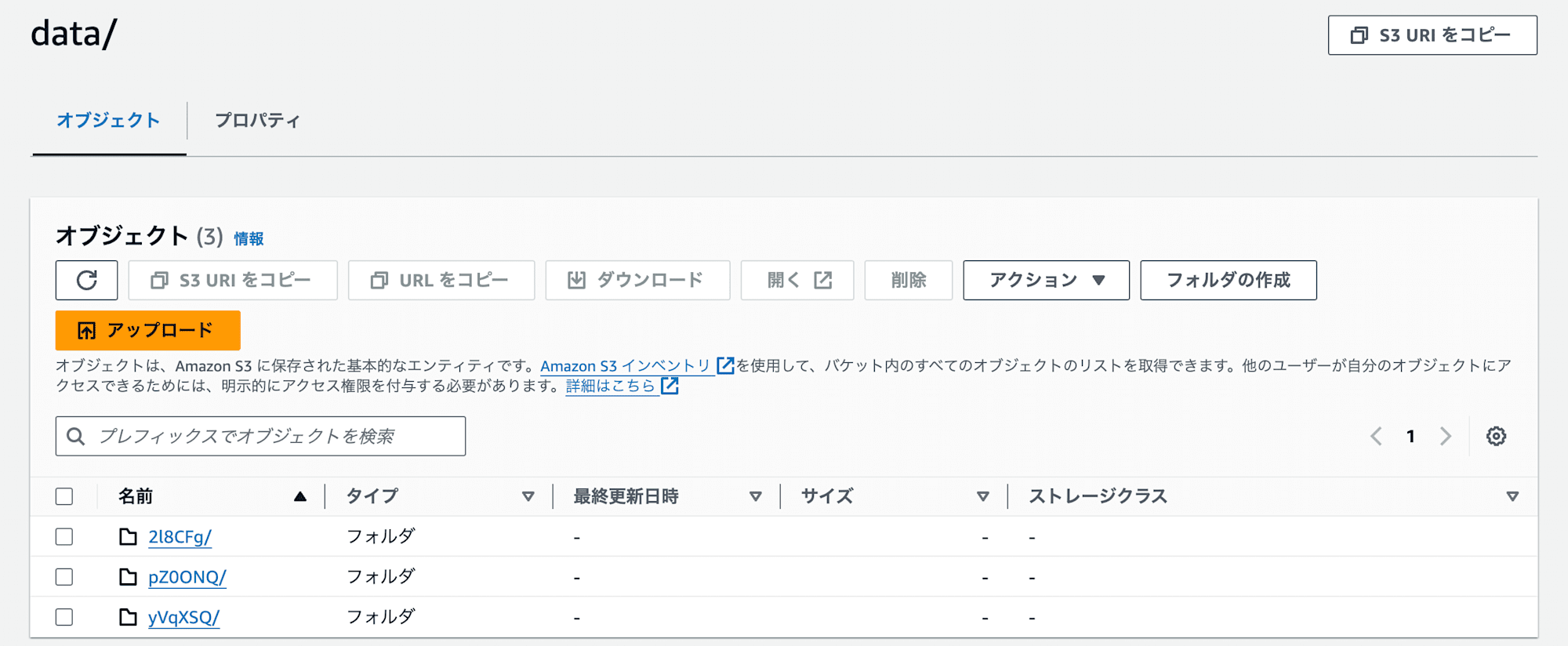
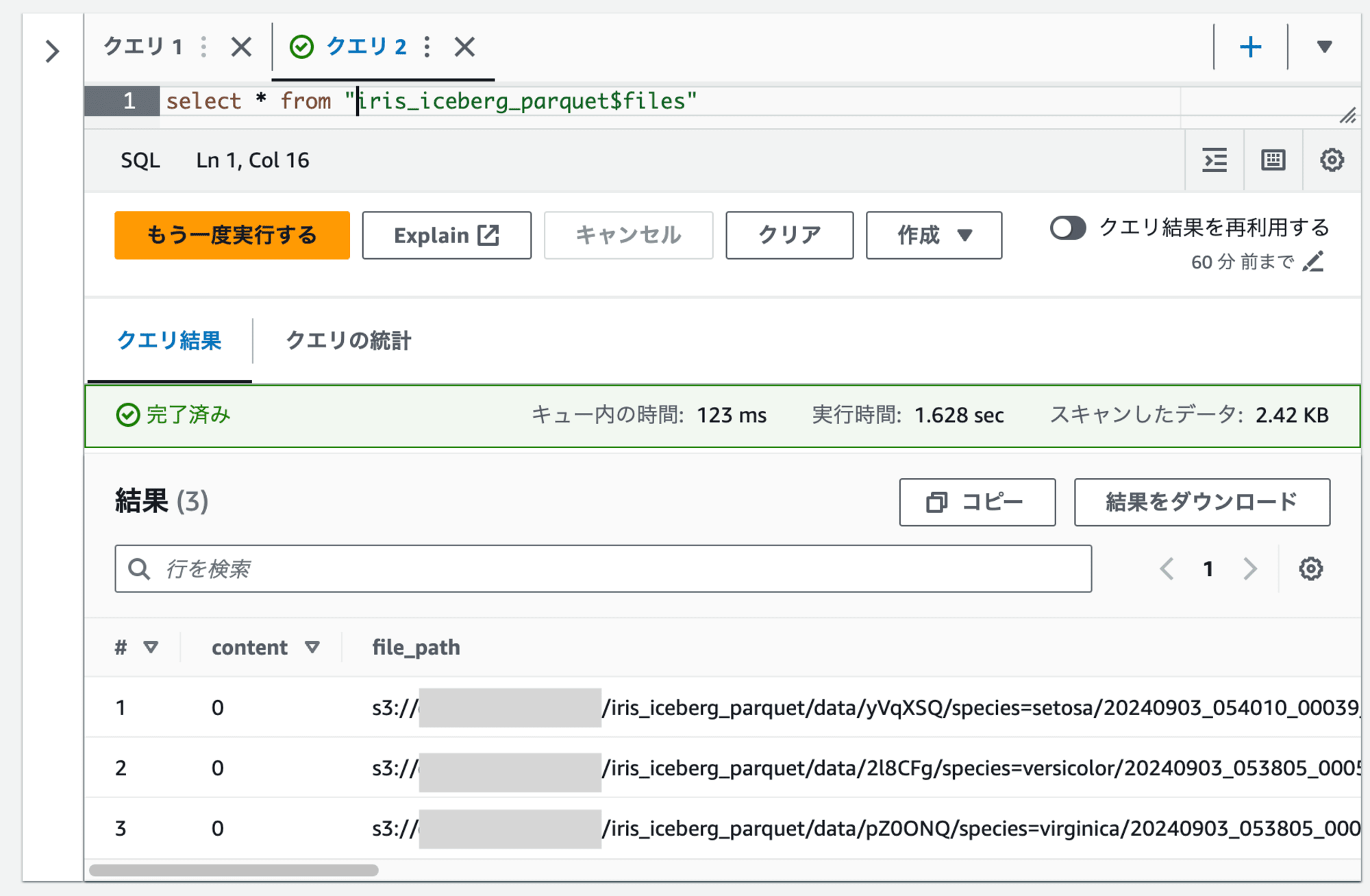
データファイルが削除されるのが期限がきれてからであるのは覚えておく必要があります。
最後に
今回は簡単な例で、AthenaのメンテナンスコマンドによりどのようにS3上のファイルが変化するかを確認しました。
AthenaのユーザーとしてはIcebergテーブルの裏側のファイルの配置がどのようになっているか完全に把握する必要は必ずしもありませんが、ファイルがたくさんできることで性能低下やコスト増が起こることを理解し、それを防ぐために適切なタイミングでメンテナンスコマンドを実行する目的で、このような例を知っておくことは重要と思います。
データファイルの追加については、メタデータファイルにも記載がされています。以下の記事などを確認して、メタデータファイルの仕様についても理解しておくとよりIcebergテーブルの活用がしやすくなるかもしれません。









